
一文详解贝叶斯优化(Bayesian Optimization)原理
参考资料:
Expected Improvement formula for Bayesian Optimisation
通俗科普文:贝叶斯优化与SMBO、高斯过程回归、TPE
理解贝叶斯优化
A Tutorial on Bayesian Optimization
贝叶斯优化是一种求解函数最优值的算法,它最普遍的使用场景是在机器学习过程中对超参数进行调优。贝叶斯优化算法的核心框架是SMBO (Sequential Model-Based Optimization),而贝叶斯优化(Bayesian Optimization)狭义上特指代理模型为高斯过程回归模型的SMBO。
- 输入:
,一般
,即参数在20个以内。
- 可行集(feasible set)A: 一般是超多边形(
)或d维的simplex(
)
- 在使用贝叶斯优化时,目标函数f:
- 需要是连续函数
- 评估成本昂贵,能允许执行的次数有限
- 是黑盒,公式/特征未知,例如:不是凹函数、线性函数之类的。
- 因为不对函数做任何假设,所以只能访问f,不能访问其一阶、二阶导数。
- 可以有噪声,但需要假设每个观测值的噪声是独立同分布,均值为0,方差恒定。
SMBO是一套优化框架,也是贝叶斯优化所使用的核心框架。它有两个重要组成部分:
- 一个代理模型(surrogate model),用于对目标函数进行建模。代理模型通常有确定的公式或者能计算梯度,又或者有已知的凹凸性、线性等特性,总之就是更容易用于优化。更泛化地讲,其实它就是一个学习模型,输入是所有观测到的函数值点,训练后可以在给定任意x的情况下给出对f(x)的估计。
- 一个优化策略(optimization strategy),决定下一个采样点的位置,即下一步应在哪个输入x处观测函数值f(x)。通常它是通过采集函数(acquisition function) 来实现的:
采集函数通常是一个由代理模型推出的函数,它的输入是可行集(feasible set)A上的任意值,输出值衡量了每个输入x有多值得被观测。通常会从以下两方面考虑: - 有多大的可能性在x处取得最优值
- 评估x是否能减少贝叶斯统计模型的不确定性
采集函数通常也是容易求最优值的函数(例如:有公式/能算梯度,等),下一个采样点就是可行集上的最大值点,即使采集函数的取最大值的点。
该框架的主要流程是:
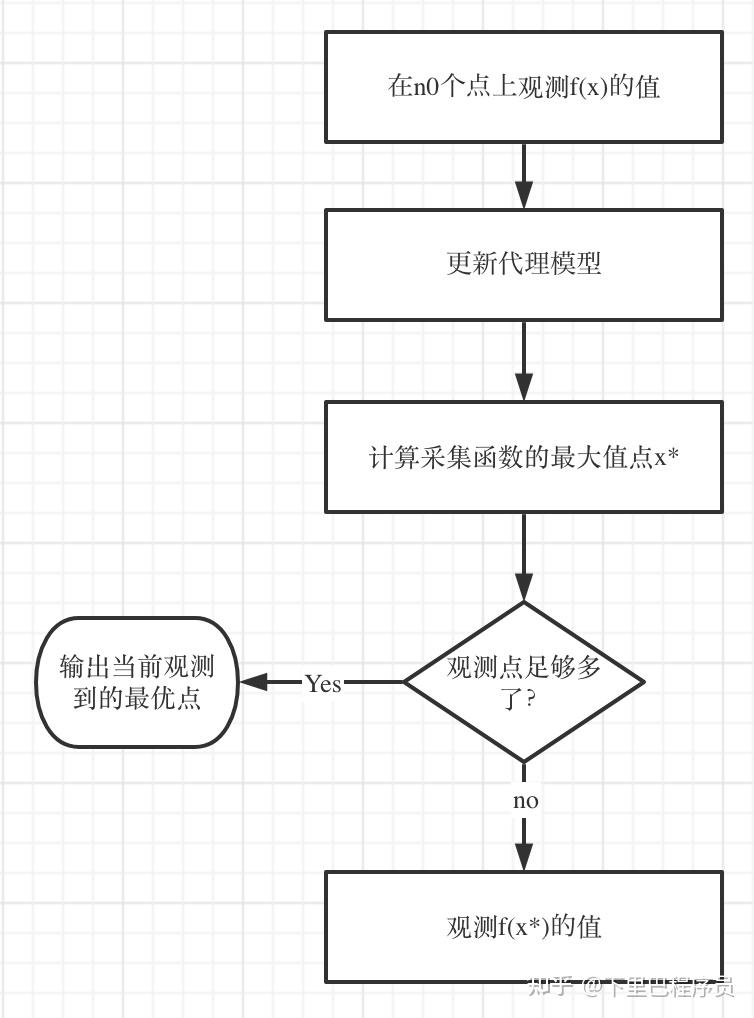
代理模型可以有很多,高斯过程、随机森林……等等。其中,贝叶斯优化(Bayesian Optimization) 狭义上特指代理模型为高斯过程回归模型的SMBO。
随机过程(Stochastic/Random Process)可以理解为一系列随机变量的集合。更具体地说,它是概率空间上的一族随机变量{X(t),t∈T}, 其中是t参数,而T又被称作索引集(index set),它决定了构成随机过程的随机变量的个数,大部分情况下,随机变量都是无限个的。
- 当T={0,1,2,...}时称之为随机序列或时间序列
- 参数t经常被解释为时间。
- 参数空间T是向量集合时,随机过程{X(t),t∈T}称为随机场。
- 随机过程有时也被称为随机函数(Random Function),因为它也可以被理解为函数值是随机变量的函数。换句话说,函数是两个变量的值之间的一一映射,而随机过程是一个变量的值到一个随机变量间的一一映射。

X(t)表示系统在时刻t所处的状态。的所有可能状态构成的集合为状态空间,记为S。
随机过程的直观理解
随机过程的直观含义是我们在 t=0 时刻(此时此刻)来考虑未来每个时间点会发生的情况。
例如,当我们把t解释为时间,而X(t)解释为粒子位置时,随机过程就可以被直观地理解为粒子的一种随机运动,它在每个时刻下的位置都是随机的,并且不同时刻t1和t2对应的X(t1)和X(t2)是相关的,它们的相关性由协方差cov[X(t1),X(t2)]定义。
辨析随机变量和随机函数
假设:
- x是一个变量
- X是一个随机变量,它服从一个概率分布P(X<t)=p(t)
- f是一个函数,例如:f(x)=x+1
- g是一个随机函数
那么有:
- f(x)代表一个因变量,当x确定时,也确定。例如:f(x)=x+1,f(1)=2
- f(X)代表一个随机变量,它的随机性是随机变量X带来的,所以它的概率分布也跟的概率分布有关。例如:f(x)=x+1,P(f(X)<t)=P(X+1<t)=P(X<t?1)
- g(x)也代表一个随机变量,但它的随机性是随机过程g带来的。
高斯过程(Gaussian Process)是一类随机过程{F(x),x∈A},它的任意n维分布 (n也是任意的)都服从多元正态分布,即:对任意有限个
,
的任意线性组合
都是一个正态分布。
正如一个正态分布可以通过指定均值和方差来确定,一个高斯过程可以通过指定均值函数 m(x) 和协方差函数 K(x,x′)唯一确定:
则高斯过程可以表示为:
均值函数定义了每个索引x对应的随机变量(同时也是正态分布变量)F(x)的均值;而协方差函数不仅定义了每个索引的方差K(x,x′),还定义了任意两个索引x1、x2对应的随机变量F(x1)、F(x2)之间的相关性K(x1,x2)。
在高斯过程模型里,协方差函数也被称作核函数(Kernel function)。
高斯过程回归(Gaussian Process Regression)就是使用高斯过程模型F(x)去拟合目标函数f(x)。
让我们先回顾一下,使用正态分布去拟合一个随机变量X的步骤:
- 建模前,我们知道正态分布的均值和方差都是常数,分别假设为μ和。
- 对随机变量X进行t次采样,得到观测值(简记为
)
- 根据观测值计算出最优的μ和σ值,由此确定最终正态分布的样子,从而完成对X的拟合
高斯过程回归也是类似的:
- 建模前,我们需要事先指定好均值函数 m(x) 和协方差函数 K(x,x′),它定义了高斯过程F(x)的先验分布。
- 有一些参数会存在于均值函数和协方差函数中。前面提到的正态分布拟合就像是一种简化:m(x)=μ,
,这里μ和σ可以被理解为是两个参数。
- 选择t个采样索引
(简记为
),它们同样也是高斯过程里对应的随机变量
(简记为
)的观测值
- 根据观测值调整均值函数和协方差函数里的参数,由此确定最终高斯过程的样子,从而完成对函数f(x)的拟合。
常用均值函数
- 常数函数
这里μ是一个参数。即使将均值统一设置为常数,因为有方差的作用,依然能够对数据进行有效建模。 - Parametric Function
这里,
都是参数。
常用协方差函数
在回归任务里,由于目标函数f是连续函数,因此对协方差函数最基础的要求是有该性质:
x与x’距离越近时,f(x)与f(x’)相关性越大。即:
常用协方差函数有:
- Power exponential / Gaussian
这里,不是标准的L2范式的写法,d是自变量x的维度数量,即参数的个数。
是d+1个参数。
- Màtern
是modified Bessel functions of the second kind。
高斯过程回归模型里的参数(主要是均值函数和核函数里的参数),是根据观测到的数据自动地“学习”出来的。“学习”的方法就是最大后验估计(MAP,Maximum A Posterior estimate),选择在观测值已知的情况下最可能的参数值。
η代表参数集合, 代表在得到所有观测值的情况下,参数的概率分布。
使用贝叶斯公式进行转换:
这也是以高斯过程为代理模型的SMBO又被叫做贝叶斯优化的原因。
由于分母与参数无关,因此只需要最大化分子:
是给定参数的情况下,得到所有观测值的概率。
P(η)是参数取值的先验概率,在某些问题,可以假设某些参数更可能被使用。但更常见的情况是假设其为等概率分布,那么MAP就是退化为最大似然估计(MLE, Maximum Likelihood Estimate),即选择使观测值最可能出现的参数值:
由于在高斯过程中,观测点 对应的随机变量构成的多维随机变量[
](简记作
)服从多元正态分布。其中,
- 分布的均值是一个t维向量:
。其中,
代表第i个随机变量
的期望/均值
。
- 分布的协方差矩阵是一个t×t的矩阵,记作:
的t个观测点
(简记作
)构成的多维变量是该多元正态分布的其中一个样本:
概率密度函数为
由于观测点 和观测值
是已知的,因此,它是一个以参数为变量的函数,我们可以选择使该概率(密度)最大化的参数值。
转化为对数似然函数:
要最大化它,即是最小化:
它是一个已知公式可以求梯度的函数,因此在编程中可以通过梯度下降等方法去求解其最优值。
在SMBO框架下,代理模型预测的不仅仅是函数值f(x),而是它的后验分布 ,即,在已知t个观测点的值的情况下,f(x)取不同值的概率。
由于在高斯过程里,也符合多元正态分布,因此就是多元正态分布的条件分布(或边缘分布)。这个分布服从正态分布,其均值和方差如下:
其中,
由于均值函数m(x)、协方差函数K(x,x′)都是确定公式的函数,公式里的参数也确定下来了,因此μ(x)和 都是确定的函数,对任意给定的x,都可以计算出值来。
通常,我们使用这个后验分布的期望/均值来作为函数值f(x)的预测值:
【命题1】对任意,
,都有
。证明见附录。
因此,对于已经观测到的点 ,我们就有:
因此,拟合出来的模型就像这样:
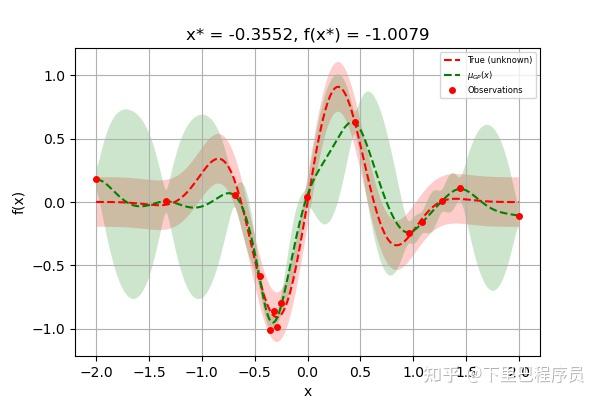
绿色阴影部分是预测的95%置信区间。
由于代理模型输出了函数f的后验分布 ,我们可以利用这个后验分布去评估下一个采样点应该在哪个位置。由于在采集函数阶段我们讨论的都是后验分布,因此后文中将省略条件部分,提到F(x)时指的都是
。
通常做法是设计一个采集函数 ,它的输入相当于对每个采样点x进行打分,分数越高的点越值得被采样。
一般来说,采集函数需要满足下面的要求:
- 在已有的采样点处采集函数的值更小,因为这些点已经被探索过,再在这些点处计算函数值对解决问题没有什么用
- 在置信区间更宽(方差更大)的点处采集函数的值更大,因为这些点具有更大的不确定性,更值得探索
- 对最大(小)化问题,在函数均值更大(小)的点处采集函数的值更大,因为均值是对该点处函数值的估计值,这些点更可能在极值点附近。
有非常多种采集函数可供选择,这里简单介绍一些作为例子。
当我们已经采样过t个点之后,总会有一个最优点 ,使得:
假设我们还可以再观测一轮,得到F(x)=f(x),最优点将在f(x)和 之间产生。不妨令
由于现在 是一个随机变量,因此我们可以计算它的期望:
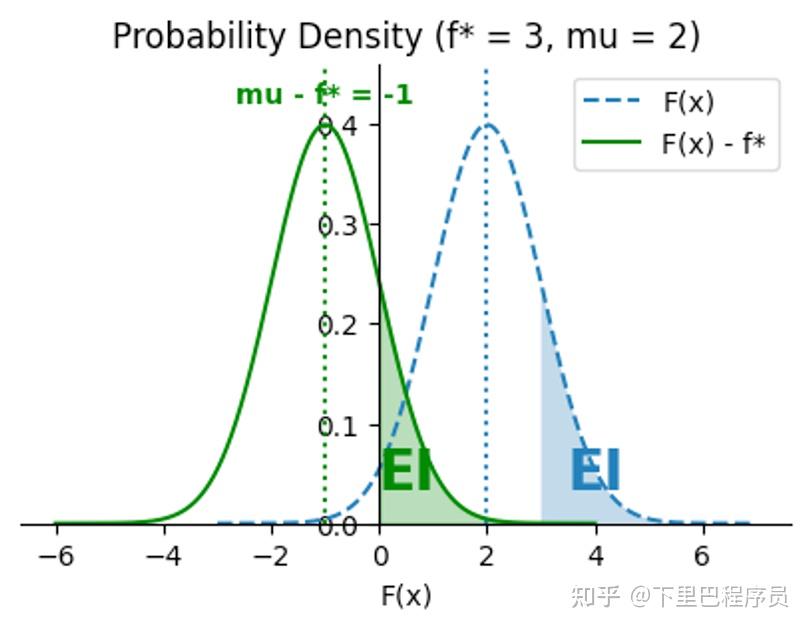
其中,μ(x)和σ(x)是正态分布F(x)的均值和标准差,即后验均值和标准差 。
为标准正态分布的概率密度函数:
而为标准正态分布的分布函数:
也是一个仅以x为自变量的函数,它的最大值点就是下一个采样点。
由于有公式,计算不费劲,也可以求梯度,找到它的最大值/极大值有很多种现成的方案可以做到,相比于求原目标函数f(x)的最值要简单得多。
推导过程
由于F(x)是正态分布,因此可以通过其概率密度计算出期望:
令k=z?μσ(也是把随机变量F(x)标准化),通过换元法可以得到:
由于对,有
。因此
由于,继续化简:
由于φ(x)是偶函数,且Φ(x)+Φ(?x)=1,则有
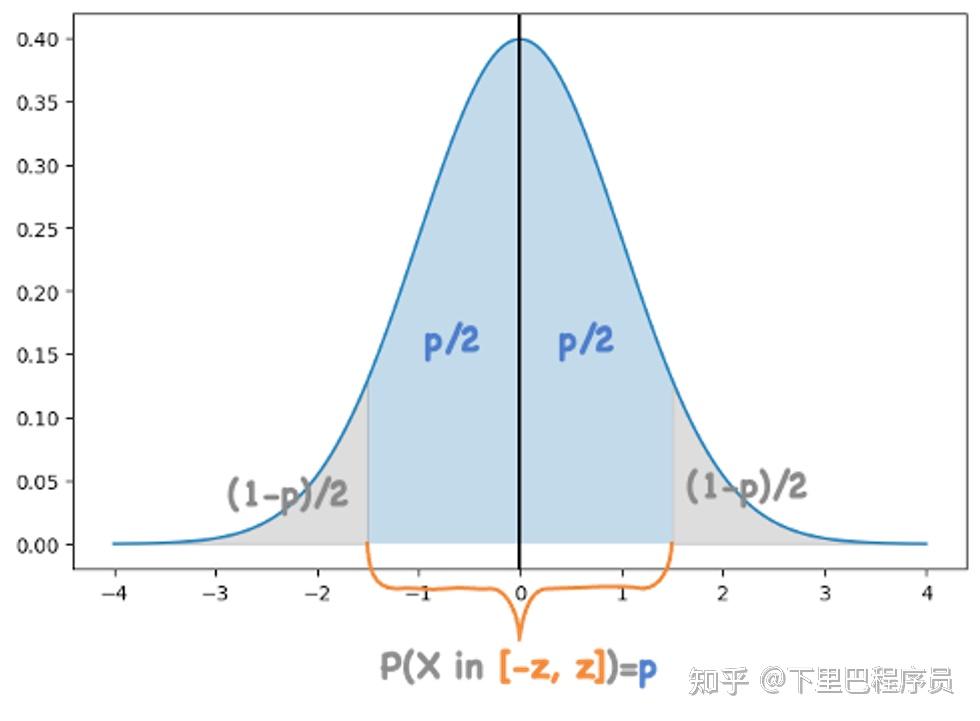
对于标准正态分布 ,给定任意关于x=0对称的区间[?z,z],可以通过对概率密度进行积分计算出一个概率p,表示符合标准正态分布的随机变量的值落在该区间的概率为p。
z和p是一一对应的,假设对于给定置信水平p,随机变量X落在置信区间[-z,z]的概率为p, ,显然
就是
的反函数。而由标准正态分布概率密度函数的对称性可知:
由于 ,它可以由标准正态分布转化过来:
那么对于 ,就有:
也就是说,当给定置信水平p时,其置信区间就为 。
可以采用该置信区间的边界作为采集函数。例如,在本文中我们讨论最大化f(x)的优化问题,通常就会使用区间的右边界UCB(Upper Confidence Bound):
其中z是超参数,由想要的置信水平p决定:z=δ(p)。
UCB越大,说明在该位置有更高的可能性找到更大的值。
同理,在最小化问题中,通常就会使用区间左边界LCB(Low Confidence Bound)。为了使我们总是找采集函数的最大值点,实际上的采集函数将是左边界的相反数,即:
【命题1】对任意
令 ,那么有
上述式子需对任意K(x,x′)都成立。列出方程组,得:
由于 可以求逆,因此它是满秩的,这意味着上面的方程组一定有唯一解。
经过变换得出:
由于右侧的项都是一样的,而左侧 各有不同,要想使他们相等,就必须等于0。因此解得:
故有:对任意 ,
,都有
。
